From Advertising to Engineering: Technical Lessons from Building DIALØGUE
I migrated from AWS to GCP and achieved 92% cost reduction with 10x faster performance—here's what I learned ditching "best practices" for pragmatic architecture that actually works.
*This is the technical deep-dive companion to my introduction of DIALØGUE. If you haven't read about what DIALØGUE is and why I built it, start there!*
The Journey: From Advertising Professional to Full-Stack Engineer
Okay, let's address the elephant in the room – yes, I come from advertising. Yeah, media plans and creative briefs, not data structures and algorithms. But here's the funny thing: understanding how systems work, whether it's a marketing funnel or a distributed architecture, requires the same analytical mindset. The difference? In engineering, when you mess up, the computer tells you immediately. No waiting for campaign results haha.
Building DIALØGUE has been… intense. It's not just writing code (though there's been plenty of that). It's architecting a complex system that somehow needs to orchestrate multiple AI services, handle asynchronous workflows, and not fall apart when users do unexpected things. Let me share what this journey has actually taught me – the good, the frustrating, and the "why didn't anyone tell me this?" moments.
Architecture Decisions: Why Complexity is the Enemy
Here's something nobody tells you when you're starting out: complexity is not your friend. I learned this the hard way. Like, really hard. Picture me drowning in CloudWatch logs, trying to figure out why my beautifully architected system was… well, not working. T.T
Initial Architecture (Overly Complex)
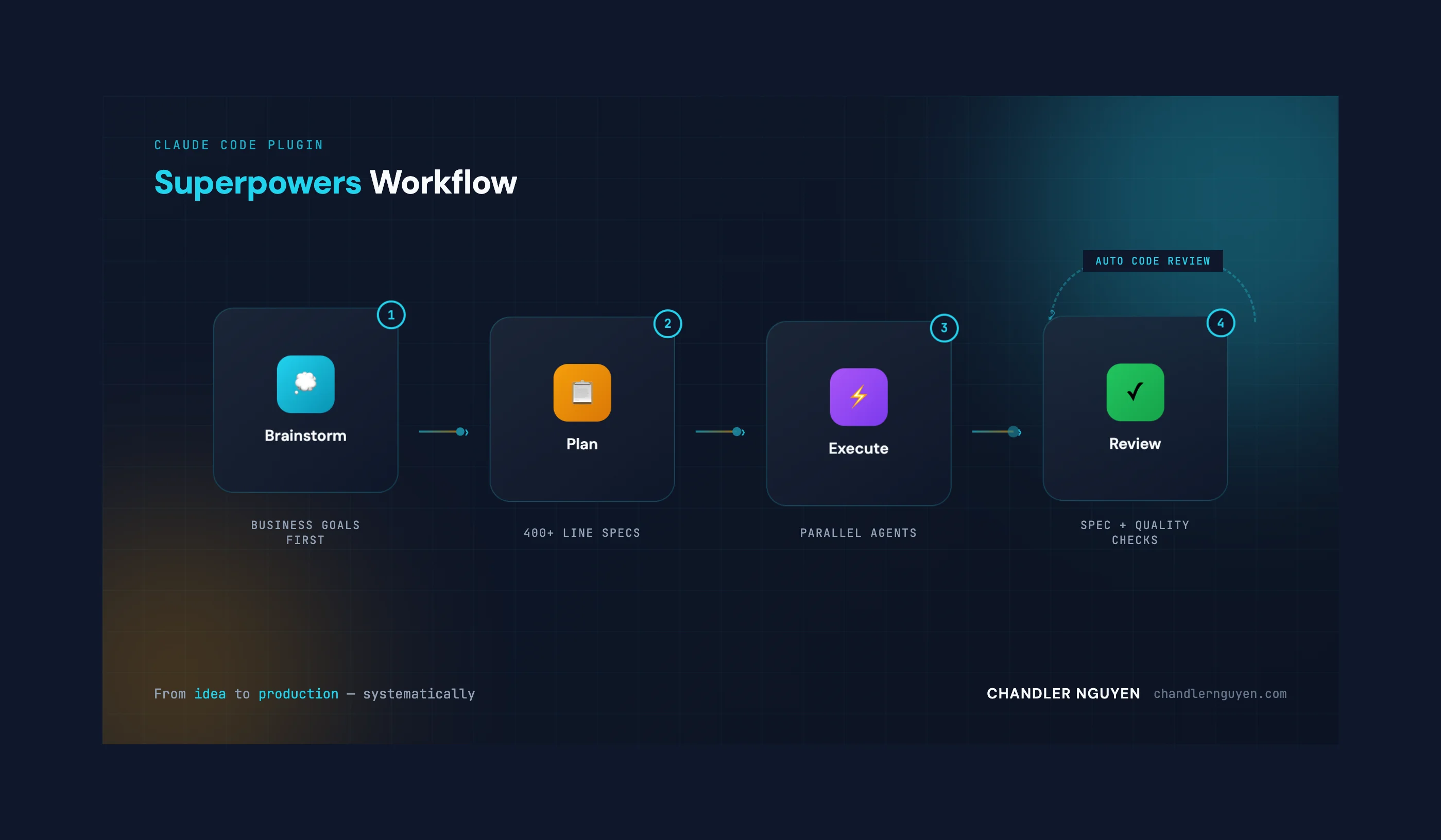
So I started with LangGraph for orchestration. Why? Because the graph-based approach seemed so elegant! It would give me flexibility! It would scale beautifully!
Reality check: It was painfully slow. Even running locally. Even with their cloud deployment. All that beautiful abstraction was just… overhead. Lots and lots of overhead.
Final Architecture (Pragmatically Simple)
After much soul-searching (and debugging), here's what actually works:
```
Frontend (Next.js) → API Gateway → Cloud Run Services → Cloud Workflows → Cloud Storage
↓
Supabase (Auth + Real-time + PostgreSQL + Edge Functions)
```
Note: We migrated from AWS Lambda/Step Functions to GCP Cloud Run/Workflows in July 2025, achieving 92% cost reduction and 10x performance improvement.
The Big Revelation: When I switched to direct Supabase queries instead of wrapping everything in APIs, I got a 10x performance improvement (450ms → 45ms). All that "proper" API layering? It was just slowing everything down. This database-first architecture became the foundation of our GCP migration.
AI Model Selection: Beyond the Hype
The Model Landscape Reality
Okay, let's talk about AI models. I've tried them all. Like, really tried them – not just played around for an afternoon. After months of testing (and burning through more API credits than I'd like to admit), here's what actually works when you're building something real:
My Current Go-To Stack:
- Claude (via Claude code) & Gemini 2.5 Pro (via Gemini CLI): My core development duo. These two models have become so capable that they've essentially replaced everything else in my workflow.
- Claude Sonnet 4 API: Powers DIALØGUE's script generation with temperature 0 for JSON reliability
What My Stack Used To Include:
DeepSeek: I used to rely on this for debugging tricky bugs, especially late-night troubleshooting sessions. But once Claude 4 and Gemini 2.5 Pro arrived? They handle those edge cases just as well, if not better. The evolution in model capability made specialized debugging models redundant for my workflow.
What Actually Works:
Here's where things get interesting: Each model is already incredibly powerful on its own. Claude is brilliant at architectural thinking and complex reasoning. Gemini 2.5 Pro? Absolutely phenomenal at implementation and maintaining context across massive codebases. The jump from Gemini 2.0 to 2.5 was insane – I could literally feel the difference. Faster responses, 1M token context window (yes, really), and it actually understands what I'm trying to build.
But here's where the real magic happens: when you get them to critique each other's work. I'll have Claude design an approach, then ask Gemini to review and suggest improvements. Or Gemini will generate a solution, and I'll have Claude analyze it for edge cases or architectural concerns. That back-and-forth, that collaborative critique process – that's where you find the breakthrough solutions neither would have reached alone.
What Didn't Work (Despite the Hype):
- OpenAI o1/o3: Everyone's talking about these, but for actual development? Too slow, too expensive, and honestly not that much better for my use cases.
- GitHub Copilot Workspace: Great idea, but those token limits… I kept hitting the ceiling whenever I tried to do anything substantial
The Real Insight: You know what nobody tells you? Different models fail differently. Early Gemini would get stuck in these weird loops on certain errors – just couldn't see the problem. Claude would spot it immediately. But then Claude would overthink simple implementations that Gemini would nail in seconds. The trick isn't finding the "best" model – it's knowing when to switch.
Full-Stack Development: Wearing Multiple Hats
The Terminal Strategy
Here's something practical that actually saved my sanity: separate terminal windows for different contexts. Sounds simple? It's game-changing.
```bash
# Terminal 1: Frontend Developer Me
cd podcast_generator_frontend_v2
npm run dev
# This is where I think about React components and user experience
# Terminal 2: Backend Developer Me
cd gcp_services
./deploy/deploy-service.sh [service-name]
# This is where Cloud Run services live (much happier than Lambda!)
# Terminal 3: Database Me
supabase start --workdir supabase
# Local Supabase for testing, production for real work
```
I know it sounds ridiculous, but physically switching between terminals helps my brain switch contexts. Frontend me and backend me are different people, and they need their own spaces.
Cross-Stack Communication
Working solo on full-stack is weird. You're basically having conversations with yourself. So I started leaving notes:
```
// Note from Frontend Me to Backend Me
/**
* BACKEND TODO:
* - Need endpoint GET /api/podcasts/:id/segments
* - Should return: { segments: Array<{id, title, status, content}> }
* - Must handle: 404 (not found), 403 (unauthorized)
* - Real-time updates via Supabase subscription would be ideal
* - Future me will thank you for error handling!
*/
```
```
## Backend Developer Summary for Frontend Integration
Current State:
- Endpoints implemented: POST /podcasts, GET /podcasts/:id
- Authentication: Bearer token via Supabase JWT
- Real-time: Supabase channel "podcast-updates"
Next Frontend Tasks:
1. Implement podcast creation form
2. Subscribe to real-time updates
3. Handle error states (401, 403, 404, 500)
```
These little notes? Absolute lifesavers when I come back to code after a week and have no idea what past-me was thinking.
Key Technical Takeaways
1. Systems Thinking Transcends Domains
My advertising background taught me to think in systems – user journeys, conversion funnels, attribution models. These mental models translate directly to:
- Distributed system design
- User experience flows
- Performance optimization
- Error handling strategies
2. Production-First Mindset
# What I learned to prioritize
if works_in_production and meets_user_needs:
ship_it()
else:
fix_only_blockers()
# Perfect is the enemy of done
3. Full-Stack Competency is Real
Building DIALØGUE required:
- Frontend: React 19, Next.js 15, TypeScript, real-time subscriptions, WebSocket management (fixed memory leaks!)
- Backend: Python 3.12, Cloud Run (14 microservices), Cloud Workflows, PostgreSQL (via Supabase)
- Infrastructure: GCP (migrated from AWS), API Gateway, Cloud Storage, Vercel for frontend
- AI/ML: Claude 4.0, Perplexity API, OpenAI TTS, temperature optimization (0 for JSON)
- DevOps: Docker containers, Cloud Build, monitoring, JWT security (P-256 migration)
- Database: PostgreSQL with RLS, Edge Functions, atomic operations for race condition prevention
4. The Importance of Classical Training
Having formal software engineering training (system design, data structures, algorithms) proved invaluable. It's not just about getting AI to write code – it's about knowing what to ask for and how to architect it.
Final Thoughts
So here's where I've landed after all of this: Building DIALØGUE has completely changed how I see myself professionally. I used to be the guy who managed technical teams. Now? I can actually build alongside them. And honestly, that feels pretty amazing. :D That evolution continued when I started building a native iOS app without knowing Swift — turns out the advertising skills (taste, creative direction, knowing what "good" feels like) matter more than the coding skills.
The journey from advertising to engineering isn't just about learning syntax or frameworks. It's about rewiring your brain to think in systems, to debug methodically, and to accept that sometimes you'll spend 3 hours on a missing semicolon (okay, TypeScript catches those, but you get the point).
You know what's funny? The analytical thinking from advertising – understanding user journeys, optimizing conversion funnels, all that stuff – it translates directly to engineering. The difference is that in code, when something doesn't work, the computer tells you immediately. No waiting for campaign reports. Just immediate, brutal feedback.
The "product" is live at podcast.chandlernguyen.com. It works. It's not perfect, but it's mine. And every bug fix, every feature addition, every "aha!" moment — they're all part of this ongoing journey.
Have you ever made a big career pivot like this — from one domain into something completely different? I'd love to hear what surprised you the most about the transition. Let me know!
Cheers,
Chandler
P.S: Speaking of learning things the hard way – want to know how one tiny AI parameter change cost me $54/month? Check out One AI Parameter Change Cost Me $54/Month. It's a cautionary tale about what happens when you trust AI assistants with production code without being explicit about production constraints. Spoiler: "make it work" and "make it production-ready" are very different requests.
P.P.S: I am still figuring out this whole engineering thing, one bug at a time. Currently building AI-powered applications and trying not to break production. Come back to this blog for more later.