呢篇文章寫於2023年,部分內容可能已經有變化。
呢個星期,有啲新聞機構報道Microsoft正在將ChatGPT功能整合到Bing Search入面。因為我之前寫過「chatGPT會唔會取代Google?」,我想喺度提供多啲想法。
索引網頁內容已經唔再係障礙
據報Microsoft喺2019年向OpenAI投資咗$10億。所以兩間公司嘅合作至少已經進行咗三年。Bing Search明顯可以索引網頁,所以我哋可以假設如果OpenAI想將chatGPT嘅數據集擴展到2021年之後,網頁內容索引唔會係問題。以Microsoft嘅規模,我哋可以假設佢嘅realtime索引/爬蟲能力同Google比較應該幾好。
Bing已經有圖片、影片內容等等作為數據集嘅一部分,所以呢個對OpenAI嘅chatGPT嚟講都唔會係障礙。
Bing Search可以相當好咁rank內容嘅可信度
雖然我冇睇過Google Search同Bing Search結果嘅最新比較,但可以講兩間公司喺判斷內容可信度方面嘅能力差距應該唔會太大。所以同樣,有咗Microsoft嘅幫助,搵到最準確嘅答案對OpenAI/chatGPT嚟講可能唔會係大障礙。
一個具體嘅例子係chatGPT冇更新嘅服務評分數據,所以佢答唔到關於本地服務嘅問題,例如「我附近最好嘅水喉匠」或者「我附近最好嘅中餐廳」。呢個就係Microsoft數據集可以幫到嘅地方。
一個user interface問題
雖然有理由話ChatGPT體驗好user-friendly,但佢唔係一個one size fit all嘅體驗去回答所有問題/查詢。好多時候,用戶想要多個答案。例如,同樣嘅本地服務,用戶通常想睇到一個合適選擇嘅列表。有人會argue喺呢啲情況下,用戶需要修改prompt去問ChatGPT「俾我5個最好嘅xyz服務」而唔係「最好嘅xyz服務」。
但我會argue咁做係唔夠嘅。Search engine應該聰明到知道喺好多情況下,冇單一嘅最好答案或者一個短名單嘅最好答案。最好嘅答案係取決於情況/context嘅。
此外,我哋有事實同我哋有意見。呢兩樣嘢完全唔同。
所以點樣design一個interface可以喺多種情景下都做到最好係關鍵。例如,就算係「越南法棍包食譜」:D 咁簡單嘅嘢,呢個係截至2023年1月我從Google、Bing同ChatGPT得到嘅結果。邊個更好或者chatGPT嘅答案更好都唔明顯。
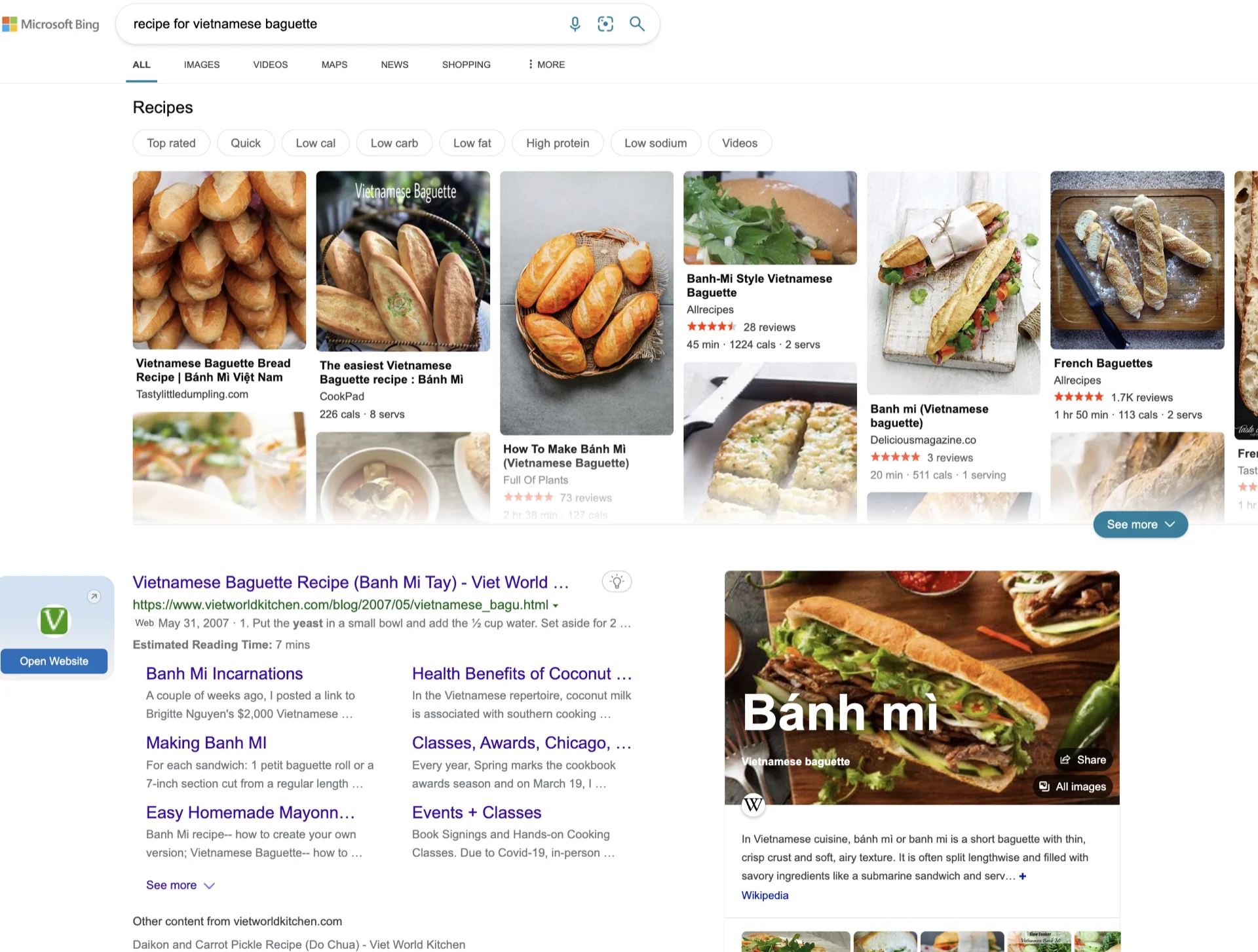
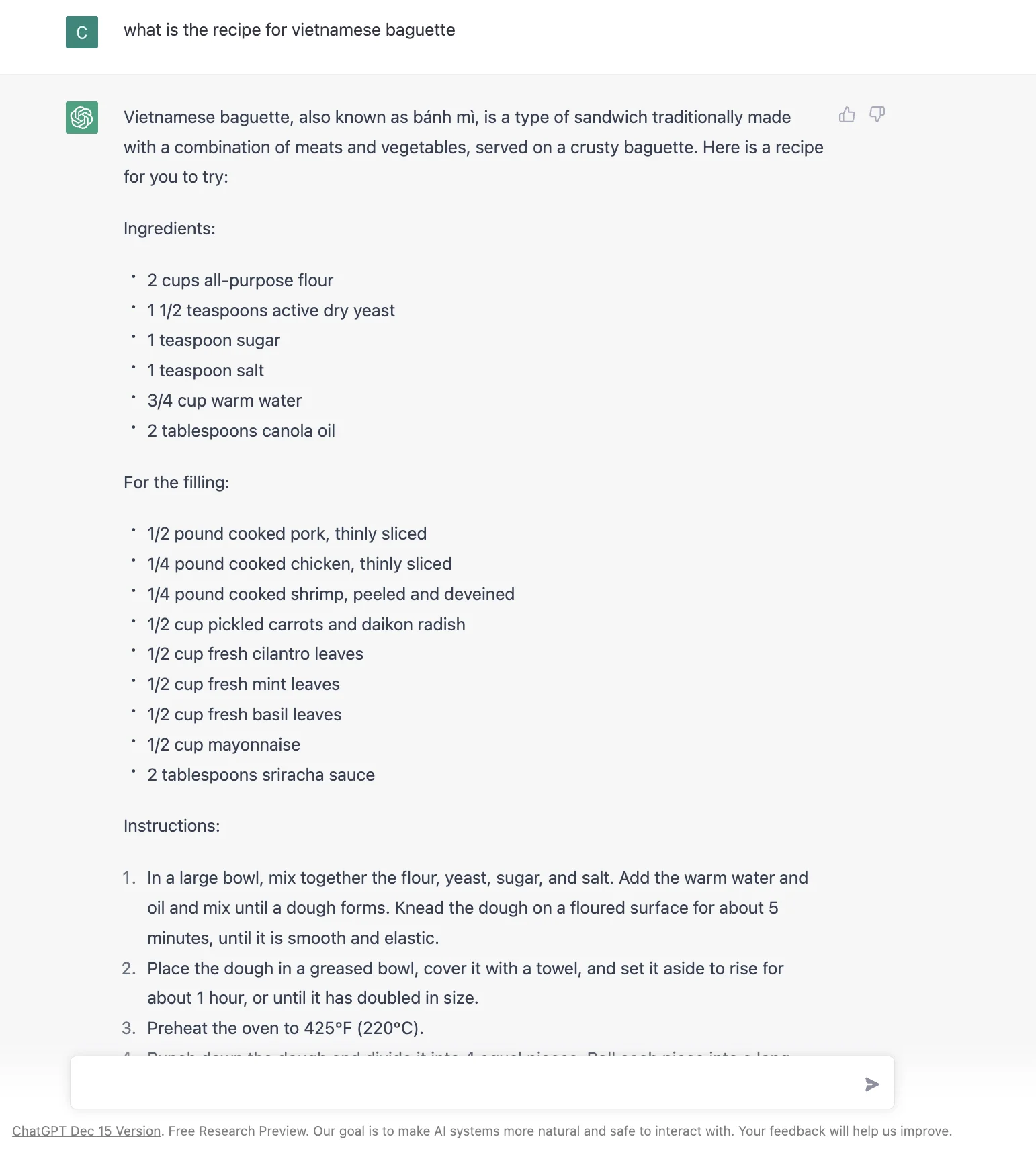
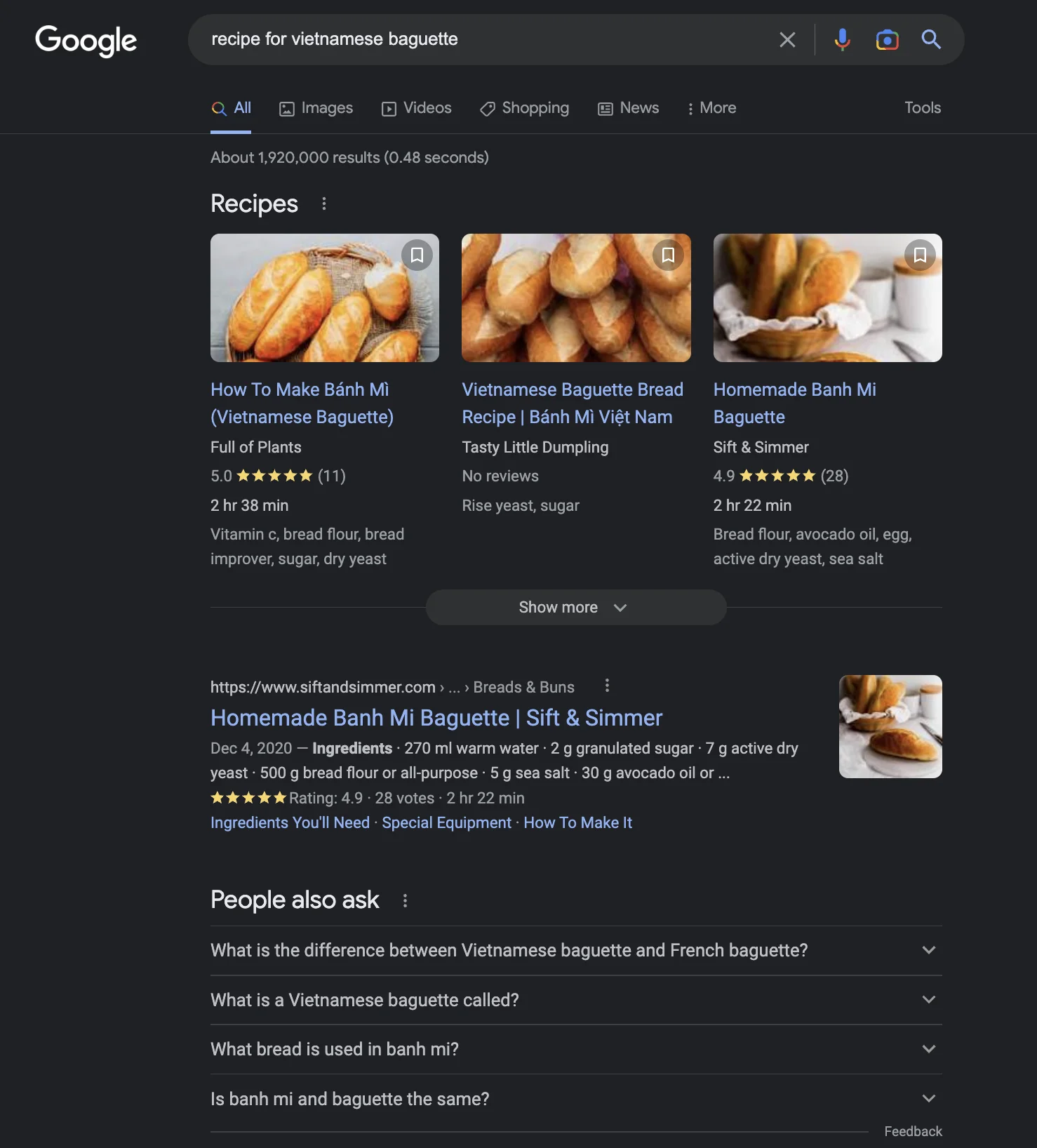
關鍵係用machine learning去根據用戶意圖動態改變search result嘅interface。我唔確定呢個有幾容易或者困難。但呢個似乎係一個合乎邏輯嘅步驟去結合ChatGPT單一答案風格同Search engine嘅強項。
一個語言助手
我會argue人哋鍾意ChatGPT唔係因為佢純粹從information search角度提供答案,而係因為佢有能力俾context再叫佢完成同語言相關嘅任務,例如寫詩、寫介紹、寫文章等等。
呢個use case同search engine好唔同,更接近生成PowerPoint narratives或者喺Microsoft Word寫嘢嘅能力。所以我其實覺得Microsoft將唔同嘅OpenAI能力整合到Office 365 suite嘅消息係一個更好嘅新聞。
語言嘅局限
Jacob Browning同Yann Lecun喺2022年8月寫咗一篇關於AI同語言局限嘅出色文章,係喺ChatGPT向公眾開放之前。雖然佢哋嘅文章reference嘅係LaMDA,但內容基本上適用於chatGPT或者任何其他大型語言模型。篇文好長,如果你想知重點,以下係:
Google嘅一個工程師最近宣稱Google嘅AI chatbot LaMDA係一個人,引起咗各種反應。LaMDA係一個大型語言模型(LLM),設計嚟預測俾佢任何文字之後最有可能出現嘅下一組字。
有啲人嗤之以鼻,有啲人則建議下一個AI可能真係一個人。反應嘅多樣性突顯咗一個更深層嘅問題:隨住呢啲LLM變得越嚟越普遍同強大,對點樣理解佢哋嘅共識越嚟越少。根本問題係語言嘅有限性。好明顯呢啲系統注定只能有淺層嘅理解,永遠唔會接近我哋喺人類身上睇到嘅全面思維。呢個係因為語言只係一種特定嘅、有限嘅知識表達方式。
語言係一種低帶寬嘅信息傳輸方法,而且由於同音詞同代名詞經常造成歧義。人類唔需要完美嘅溝通工具,因為我哋共享非語言嘅理解。LLM缺乏發展對世界連貫觀點所需嘅理解。
雖然語言可以喺細小嘅格式入面傳達好多信息,但好多人類知識係非語言嘅,可以通過其他方式傳達,例如圖表、地圖、文物同社會習俗。呢個暗示單純用語言訓練嘅machine唔會完全接近人類智慧,因為佢只能通過一個narrow bottleneck access到人類知識嘅一小部分。
以上就係我嘅分享。你點睇?你會由Google轉去ChatGPT驅動嘅Bing,定係習慣令你留喺Google?:)
祝好,
Chandler